What is Event-Driven Architecture? A Guide for Engineers
A way of designing software so parts of the system react to events, instead of constantly calling each other directly and waiting for responses.
You’ve probably built a backend that felt clean at first, then turned brittle as soon as the app got a bit more real. A user signs up, then the system needs to send a welcome email, create a profile, notify analytics, sync billing, and maybe update a dashboard. In a simple setup, one request tries to do all of that in order.
That’s where many new backend engineers first feel the limits of straight-line thinking. One failure in the chain can slow everything down or break the whole operation. Event-driven architecture is one of the main ways modern systems avoid that trap.
If you’ve been asking what is event-driven architecture, the short answer is this: it’s a way of designing software so parts of the system react to events, instead of constantly calling each other directly and waiting for responses. The useful answer is bigger than that. It’s really a shift in how you model work, failure, scale, and team boundaries.
From Monoliths to Microservices Why EDA Matters #
A lot of developers meet backend architecture through a monolith. That’s not a bad thing. In fact, it’s often the best place to start because everything is close together, easier to trace, and simpler to deploy.
The pain starts when one user action triggers too many tightly connected steps. Think about an e-commerce checkout. The order service calls payment, payment calls inventory, inventory calls shipping, shipping updates notifications. If each step waits on the previous one, the whole experience depends on every service being healthy right now.

Where synchronous systems start to hurt #
In that checkout flow, direct calls create hidden coupling:
- One slow dependency delays everyone. If inventory is slow, the customer waits.
- One outage spreads outward. If notifications fail badly and the call chain isn’t designed well, order processing can fail too.
- Scaling gets awkward. You often need to scale the part receiving traffic, even if the actual bottleneck is further downstream.
- Teams step on each other. A change in one service contract can force coordinated releases across multiple teams.
That’s why event-driven architecture matters. Instead of saying, “Order service, call these five systems right now,” the order service says, “An order was placed.” Other services react if they care. If they don’t, they ignore it.
Practical rule: Use events when the business fact matters more than the immediate response chain.
That decoupling is one reason EDA has become a core skill. IBM notes that 37% of companies already implement event-driven architecture and another 26% plan to adopt it, showing a clear move toward real-time event processing in modern software (IBM on event-driven architecture adoption).
Why this matters for your career #
As systems move from one large codebase to distributed services, backend engineers need a stronger architectural mindset. You don’t just write endpoints anymore. You design how information moves through a system under load, during failure, and across team boundaries.
If you want to grow into that mindset, this guide on thinking like an engineer is worth reading alongside architecture topics like this one.
EDA isn’t just “microservices stuff.” It’s a way to build systems that react to what happened, instead of forcing every part of the system into the same request.
The Core Components of Event-Driven Architecture #
The easiest way to understand event-driven architecture is to stop thinking about servers for a moment.
Think about a magazine subscription service. A new issue gets published. The publisher doesn’t personally call every subscriber. The postal system routes copies where they need to go. Subscribers receive the issue when it arrives and do their own thing with it.
That mental model maps surprisingly well to backend systems.

Event #
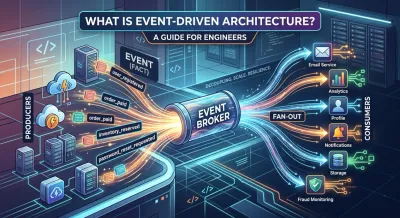
An event is a record that something happened.
Not a command. Not a request for permission. A fact.
Examples:
- user_registered
- order_paid
- password_reset_requested
- inventory_reserved
The wording matters. Good events usually describe something that already occurred. That makes them easier to reason about and safer for other services to consume.
Producer #
An event producer is the part of the system that emits the event.
In the magazine analogy, this is the publishing house. In software, it might be your checkout service, auth service, or billing service. A producer notices a business event and publishes it.
The producer shouldn’t need to know every consumer. That’s one of the main design wins. The order service doesn’t need a hardcoded list of “analytics service, email service, warehouse service, loyalty service.” It just publishes order_placed.
Broker #
The event broker is the delivery layer.
This is the postal system in the analogy. In real systems, that broker could be Kafka, RabbitMQ, Redis streams, or a cloud service such as AWS EventBridge. The broker receives events, stores or routes them, and makes sure consumers can process them.
A broker gives you breathing room. Producers can keep publishing even if consumers process later. That buffer is one reason event-driven systems handle spikes better than tightly chained request flows.
Consumer #
An event consumer subscribes to events and reacts to them.
One event can have many consumers:
| Event | Possible consumers |
|---|---|
| user_registered | email service, analytics service, profile service |
| order_shipped | notifications service, customer timeline service |
| payment_failed | fraud monitoring, support workflow, retry scheduler |
Each consumer owns its own response. That independence is what makes event-driven systems extensible. You can add a new consumer later without changing the producer.
A useful test for understanding EDA is this: can you name the business event without also naming who will react to it?
Why beginners get confused here #
New developers often mix up events and messages, or events and commands. The cleanest distinction is this:
- Event means “this happened.”
- Command means “please do this.”
That sounds small, but it changes system design. Events support looser coupling because they announce facts. Consumers decide what to do next.
Once that clicks, the rest of event-driven architecture starts making more sense.
Thinking Asynchronously Shifting from Request-Response #
Most backend developers learn APIs through request-response. A client sends a request. The server handles it. The client gets an answer. That model is concrete, predictable, and easy to debug.
It’s also only one way systems can communicate.

Phone call versus voicemail #
A synchronous API call is like a phone call. Both parties need to be available at the same time. The caller waits for the answer.
An event is closer to leaving a voicemail. You send the message and move on. The receiver can process it later.
That shift changes how you think about a backend:
- producers don’t wait for every downstream action
- consumers can be offline temporarily
- different parts of the system move at different speeds
- the system becomes less about a single transaction and more about a flow over time
If you’ve spent most of your time designing REST APIs, that can feel strange at first. This guide on REST API design best practices is still relevant, because strong synchronous design teaches useful habits. You just need to add an async mental model on top.
What you stop assuming #
In request-response systems, developers often assume:
- the other service is available now
- the answer comes back right away
- success or failure is immediate
- the caller knows who it depends on
In event-driven systems, none of those assumptions are safe by default.
That sounds harder because it is. But it also makes the system more flexible. A notification service can go down without stopping order creation. A reporting service can lag without breaking checkout. A new service can subscribe later without changing the producer.
The biggest architectural shift isn’t technical. It’s accepting that “completed business flow” and “completed HTTP request” are not always the same thing.
Why teams like this model #
Asynchronous design also changes team workflow.
When services communicate through events rather than direct calls, teams can evolve more independently. A consumer can be deployed, replaced, or extended without forcing a change in the producer. That’s valuable in growing organizations, but it’s also valuable in small teams trying to keep change isolated.
This video gives a visual explanation of blocking and non-blocking flows if you want to reinforce the model:
When request-response is still the right tool #
EDA doesn’t replace APIs. It complements them.
Use request-response when you need an immediate answer, such as authentication checks, form validation, or fetching a resource for a page load. Use events when the system should react to something over time, especially when multiple downstream actions don’t need to block the user.
Good backend engineers learn both models and choose based on the job, not fashion.
Key Benefits and Critical Trade-offs of EDA #
Event-driven architecture solves real problems. It also creates new ones. If you only learn the upside, you’ll make bad design decisions with a lot of confidence.
The best way to judge EDA is to look at the trade: more decoupling and scalability, more distributed complexity.
What EDA does well #
One major strength is buffering. Producers can publish work into a broker, and consumers can process at their own pace. That helps when traffic arrives unevenly or downstream services are slower than the frontend.
AWS notes that EDA uses eventual consistency, and that CQRS can boost query performance by 10x in benchmarks for e-commerce order processing. The same source notes Kafka clusters handling 2M+ events per second with under 1ms latency, while polling-based systems can waste 70% CPU on idle checks (AWS on event-driven architecture performance).
That matters in practical terms:
- Traffic spikes become easier to absorb. The broker acts like a cushion.
- Failures stay more local. One consumer can fail without collapsing the whole flow.
- Polling drops. Systems react when something changes instead of repeatedly asking whether something changed.
- Read and write paths can evolve separately. Patterns like CQRS make that possible.
What you pay for those benefits #
You don’t get resilience for free. You pay in complexity.
The first cost is eventual consistency. In a synchronous design, you often expect the system to be fully updated the moment a request ends. In EDA, that’s frequently no longer true. One part of the system may know about the new order before another part catches up.
The second cost is ordering. If events arrive out of order, your consumer logic can produce the wrong result unless you design carefully.
The third cost is operations. You now own more moving parts: a broker, retries, dead-letter handling, consumer lag, schema evolution, and observability across services.
A balanced decision table #
| Question | If answer is yes | EDA may fit |
|---|---|---|
| Do multiple systems need to react to one business event? | You want fan-out without hard dependencies | Strong fit |
| Must the user wait for every downstream step? | No | Strong fit |
| Do you need immediate global consistency? | Yes | Weak fit |
| Is your team early in its backend journey? | Yes | Start smaller |
| Are traffic bursts or downstream outages a real concern? | Yes | Strong fit |
Don’t ask whether EDA is modern. Ask whether the business flow can tolerate delay, duplication handling, and more operational complexity.
The mindset that helps #
New engineers often look for the “best architecture.” That’s the wrong question.
A better question is: what failure mode hurts less? If a synchronous chain fails, the user action may fail immediately. If an event-driven flow fails, the user action may succeed while some downstream work happens later or needs retry. Many systems prefer the second trade. Some do not.
That’s architecture. You’re choosing what kind of pain your system can survive.
Essential Event-Driven Design Patterns #
Once the basic pieces make sense, the next question is how they’re arranged in real systems. That’s where patterns help. They give you repeatable ways to handle common problems without reinventing the architecture every time.

Publish subscribe #
The foundation is publish-subscribe, often shortened to pub/sub.
A producer publishes an event. Any interested consumer subscribes and reacts. The producer doesn’t know which consumers exist, and consumers don’t need to know who else is listening.
This pattern works well when one business event should trigger multiple independent actions. A user_registered event might start onboarding, analytics tracking, and welcome email delivery without creating a brittle chain of direct API calls.
Pub/sub is the pattern often considered when first asking what is event-driven architecture.
Event sourcing #
A more advanced pattern is event sourcing.
Instead of storing only the current state, the system stores the sequence of events that produced that state. If an account balance changed, or an order moved through states, the source of truth is the event history.
Confluent describes a key milestone in EDA as the integration of event sourcing and CQRS, formalized in the early 2010s, allowing systems to capture all state changes as immutable event sequences for reconstructibility and auditability (Confluent on event sourcing and CQRS).
That leads to some powerful capabilities:
- Auditability. You can inspect how the system got to its current state.
- Replay. You can rebuild state by replaying events.
- Debugging over time. You can reason about the past, not just the latest row in a table.
But event sourcing also raises the bar. You need strong event design, versioning discipline, and comfort with rebuilding projections from history.
CQRS #
CQRS stands for Command Query Responsibility Segregation.
The idea is simple: the model used to write data doesn’t have to be the same model used to read it. Writes can focus on correctness and business rules. Reads can focus on fast queries and convenient views.
That separation is useful when read patterns and write patterns pull in different directions. An order system may write compact domain events, while a customer dashboard reads from a denormalized view built for search and filtering.
How to think about these patterns #
Not every event-driven system needs event sourcing or CQRS. Many don’t.
Use this rough guide:
- Pub/sub is the default starting point.
- CQRS becomes useful when read and write needs diverge sharply.
- Event sourcing fits when history itself is central to the domain.
Advanced patterns should solve a clear problem. If you adopt them just because they sound senior, they’ll punish you later.
For a new backend engineer, the goal isn’t to memorize pattern names. It’s to understand which problem each pattern solves and what complexity it adds in return.
Common Pitfalls and How to Avoid Them #
Most beginner-friendly EDA content makes the architecture look neat and almost magical. Real systems are messier. Messages arrive twice. Consumers fail halfway through work. A downstream bug only appears under load. A test passes locally and flakes in CI.
That’s why testing and debugging matter so much. A major gap in EDA learning materials is guidance on those topics. One summary notes that over 72% of organizations use EDA, but few resources teach engineers how to verify behavior under load or failure (Wikipedia summary on EDA usage and testing gap).
Idempotency is not optional #
If your broker can redeliver a message, your consumer must handle duplicates safely. That property is called idempotency.
If order_paid arrives twice, your system shouldn’t charge twice, send two invoices, or reserve inventory again by mistake. Good consumers use deduplication logic, idempotency keys, or database constraints that make repeat processing safe.
A useful habit is to assume every important event may be retried.
Delivery guarantees are easy to misunderstand #
Developers often hear terms like:
- At-most-once
- At-least-once
- Exactly-once
The dangerous mistake is treating these as simple broker features. In practice, the outcome depends on the full system, including producer behavior, consumer logic, storage, retries, and external side effects.
“Exactly-once” sounds comforting. But if your consumer updates a database and also calls an outside payment provider, you still need to reason carefully about what happens when part of that flow succeeds and part fails.
Testing async systems requires different habits #
Unit tests still matter, but they’re not enough.
For event-driven systems, strong testing often includes:
- Producer tests that verify the right event is emitted for a business action
- Consumer tests that verify repeated delivery doesn’t break behavior
- Component tests that include the broker and validate real message flow
- Failure-path tests that simulate retries, delays, and malformed events
Tools like pytest with async support, testcontainers for broker-backed test environments, and broker-specific local setups can help. The exact stack varies. The principle doesn’t. Test the flow, not just isolated functions.
If you can’t trace an event from producer to consumer, you don’t yet have an operable event-driven system.
Observability makes or breaks production support #
In synchronous APIs, you can often follow one request through logs and status codes. In EDA, work spreads across services and time. You need stronger observability.
Use:
| Need | What helps |
|---|---|
| Follow one business action across services | correlation IDs |
| Understand retries and failures | structured logs |
| See bottlenecks and lag | metrics |
| Trace async flow across boundaries | distributed tracing |
Without that, debugging becomes guesswork. And guesswork in a distributed system gets expensive fast.
The strongest beginner move you can make isn’t picking the fanciest broker. It’s learning to build consumers that are safe to retry and systems that are easy to trace.
Your Path to Mastering Event-Driven Architecture #
The right way to learn event-driven architecture is not to jump straight into the most advanced pattern stack you can find. Start with a smaller mental model, then add complexity when you can explain why it belongs.
The core lesson is simple. EDA is about decoupling, asynchronous communication, and designing around events as facts. The harder lesson is that every gain in resilience or scalability brings extra responsibility in consistency, debugging, and operational discipline.
A practical learning order #
A strong progression looks like this:
- Learn request-response well first. If you can’t design a clean synchronous backend, async architecture will just hide problems across more services.
- Build one small project where a producer publishes an event and two consumers react.
- Add failure scenarios. Retry a message. Simulate duplicate delivery. Break a consumer and inspect what happens.
- Learn schema evolution. Events are contracts, and contracts change slowly when other systems depend on them.
- Study patterns like pub/sub, CQRS, and event sourcing only after the basics feel natural.
What to practice with tools #
Don’t keep this purely theoretical. Use real tools.
- Try a broker such as RabbitMQ or Kafka
- Model events carefully, with fields that describe facts rather than requests
- Explore schema tools such as Avro, Protobuf, or a Schema Registry
- Add logs, metrics, and correlation IDs from the start
You’ll learn more from one small system with retries and observability than from ten architecture diagrams.
How to judge your progress #
You’re making progress when you can answer questions like these without hand-waving:
- What event should this service publish?
- What can go wrong if the consumer receives it twice?
- Does this flow require immediate consistency, or can it be eventual?
- How would I test this path under failure?
- If a message disappears in practice, how would I trace it?
That’s the difference between memorizing definitions and thinking like a backend engineer.
If your next goal is a broader roadmap, this guide on how to become a backend developer connects architecture skills like EDA to the rest of the backend skill set.
If you want to go beyond reading to practice the backend skills that make event-driven systems understandable, Codeling is a strong place to do it. It teaches backend engineering through hands-on Python exercises, APIs, testing, architecture, and portfolio projects, so you build the habits that make topics like EDA much easier to learn in practical settings.