AI Programming with Python: From Developer to AI Architect
This guide is about building a career in AI through sound architectural principles, not just a model.
So, you want to master AI programming with Python. Let's be honest, most guides will point you to a long list of libraries and tell you to start building models in a Jupyter Notebook. That path is a dead end for a serious software developer.
It's the fast track to becoming a hobbyist who can create impressive demos but struggles to get hired for high-level engineering roles. Why? Because a script that predicts something in a notebook is a world away from a production-grade AI system that a real company can depend on.
Your Path From Developer to AI Architect #
This guide is different. We’re not just showing you how to call a function in a library. We’re going to teach you how to think like an AI architect.
That means approaching every problem like a senior software engineer first and an AI specialist second. It’s a crucial mindset shift. In the real world, a model with 95% accuracy that’s impossible to deploy, maintain, or scale is useless. A model with 85% accuracy that’s wrapped in a robust, testable, and scalable software system is what defines a professional career.
This guide is about building a career through sound architectural principles, not just a model. We'll focus on professional software development practices from day one—the kind of thinking that separates senior engineers from junior developers who get stuck in tutorial hell.
The real difference between an AI hobbyist and a professional is architecture. A professional builds systems designed for change, scalability, and maintenance. A hobbyist builds for the immediate result.
From Code Snippets to System Blueprints #
Too many aspiring developers get trapped in a loop. They learn one library, then another, but they never learn how to connect the pieces into a coherent system. They can write a function, but they can’t design an application.

We're going to break that cycle by focusing on what actually matters for building real-world AI products:
- The Engineering Mindset: This is non-negotiable. It means mastering essentials like version control with Git, containerizing your applications with Docker, and prioritizing clean, modular, and testable code from the start. It’s about building software that lasts.
- Architectural Patterns: You'll learn how to structure a complete system, not just a script. This includes designing scalable data pipelines, serving models through well-defined APIs, and integrating Large Language Models (LLMs) into real applications using powerful patterns like Retrieval-Augmented Generation (RAG).
- Strategic Project Building: Your portfolio should tell a story of engineering competence. We'll focus on creating end-to-end projects that prove you can deliver a finished, deployable product, not just a proof-of-concept script.
This approach is about developing a deep intuition for how systems should work, a philosophy with some parallels to the idea of "vibe coding"—but with a strict engineering backbone. It’s about understanding the flow of a system, not just copy-pasting code. If you're curious, you can read our guide on what vibe coding is and how it applies to modern development.
From mastering Python fundamentals to architecting LLM-powered applications, this is your blueprint for becoming the kind of AI engineer companies are desperate to hire.
Building Your Bedrock Software Engineering Skills #
It’s tempting to jump straight into the exciting AI work. I get it. You want to train models, build chatbots, and see the magic happen. But I've seen countless aspiring developers skip the "boring" foundational work, and it always limits their career growth.
This is the material that separates a hobbyist from a professional who builds systems that people can actually rely on. Diving headfirst into deep learning without a solid software engineering foundation is like trying to build a race car engine when you don't know how to use a wrench. The engine might turn over once, but it’s going to fall apart on the first lap.
The goal here isn't to memorize textbook definitions. It’s to adopt a professional mindset. In AI programming with Python, pros don't just write code that works—they architect systems that are modular, testable, and built to evolve.
Architecting Your Code With Object-Oriented Principles #
Object-Oriented Programming (OOP) isn't just an academic concept; it's the language of professional software engineering. When you're building an AI application, you’re orchestrating complex components: data loaders, models, preprocessors, and evaluation engines. OOP provides a structured way to manage this complexity.
Instead of a single, tangled script, you can design a DataPreprocessor class to handle cleaning and a ModelTrainer class for the training loop. This architectural decision immediately makes your code cleaner, more reusable, and far easier to debug. Want to experiment with a new model? No problem—you just swap the component without rewriting your entire pipeline.
Adopting an OOP mindset means you stop thinking in terms of scripts and start thinking in terms of components. It's the difference between a one-off experiment and a maintainable, production-ready system.
This design thinking extends to your choice of data structures. Knowing when to use a dictionary versus a list isn't trivial. Using a hash map (a Python dictionary) for a fast lookup in a feature engineering pipeline can be thousands of times faster than iterating through a list. At scale, this choice defines the performance of your entire system.
Mastering the Tools of Modern Development #
Great code doesn't exist in a vacuum. It lives within an ecosystem of tools that enable collaboration, reproducibility, and deployment. These are non-negotiable skills for any serious software developer.
- Version Control with Git: Git is the bedrock of modern development. It lets you experiment with new features on separate branches without breaking your main application. A clean Git history serves as your project's living documentation, showing not just what changed, but why.
- Command-Line Proficiency: While GUIs are helpful, the command line is the power user's environment. You’ll use it constantly to manage environments, run scripts, connect to servers, and orchestrate tools like Docker. Fluency in the terminal is a hallmark of a self-sufficient engineer.
- Containerization with Docker: Your AI model has a specific set of dependencies. How do you ensure it runs the same way on a teammate's machine or in the cloud? Docker. It solves the "it works on my machine" problem by packaging your code, dependencies, and configuration into a portable container that runs identically everywhere.
These tools ensure your work is reproducible, collaborative, and ready for production from day one. To deepen your understanding of building robust components, our guide on how to write unit tests in Python is a great next step for ensuring your code is reliable and maintainable.
This table breaks down the core competencies you need to internalize before you dive into machine learning frameworks.
Essential Software Engineering Skills for AI Development #
| Skill | Why It's Critical for AI | Learning Goal |
|---|---|---|
| Object-Oriented Programming (OOP) | Enables the design of modular, reusable, and testable systems for complex AI applications like data pipelines and model APIs. | Design a simple project using classes to represent distinct components, such as a DataLoader and a Predictor, to practice separation of concerns. |
| Data Structures & Algorithms | Essential for writing efficient code that can handle large datasets. Directly impacts system performance, memory usage, and processing speed. | Understand the trade-offs of core data structures and apply them to solve problems, like using hash maps for feature lookups or queues for data streaming. |
| Git & GitHub | The industry standard for version control and collaboration. Crucial for tracking experiments, managing code, and working effectively in a team. | Create a project, manage its history with commits and branches, and practice a full collaborative workflow using pull requests. |
| Docker Containerization | Solves the "it works on my machine" problem by ensuring your AI environment is consistent, portable, and reproducible across all systems. | Package a simple Python application and its dependencies into a Docker image, demonstrating an understanding of creating isolated environments. |
Mastering these software engineering skills first is the most reliable path to a successful and long-lasting career in AI. Don't skip the foundation.
Mastering the Core Data Science and ML Toolkit #
With a strong software engineering foundation, you're ready to learn the libraries that power professional AI programming with Python. Many developers stumble here by focusing on memorizing functions. The real skill is not just knowing the tools, but understanding how to use them to architect a clean, efficient, and maintainable workflow from raw data to a trained model.
Your journey into data manipulation begins with NumPy and pandas. These libraries force a crucial shift in your thinking. You must move away from slow, iterative for loops and adopt a "vectorized" mindset. This means performing operations on entire arrays of data at once, which is orders of magnitude faster.
Think about it from a systems perspective. A beginner might write a loop to process a million rows of sales data. An engineer using NumPy or pandas applies a single vectorized operation to the entire column, completing the job in a fraction of the time and with cleaner code.
Architecting Clean Data Pipelines #
Thinking like an AI engineer means designing data workflows that are both powerful and easy to maintain. This is where a tool like pandas becomes an architectural choice. It’s not just for loading CSV files; it’s for building industrial-strength data wrangling pipelines. A well-designed pipeline isn't a monolithic script—it's a series of clear, self-contained transformations.
The goal is to create a feature engineering workflow where each step is a modular, testable function. This architectural pattern ensures that if a business requirement changes, you only need to modify one component, not untangle a mess of code.
This modular approach is paramount. Business needs are dynamic, and your system must adapt without a complete rewrite. For instance, you can design a pipeline with distinct, logical stages:
- Data Ingestion: A function or class responsible for one thing: loading raw data from its source.
- Initial Cleaning: A component dedicated to handling missing values and standardizing data types.
- Feature Engineering: A set of functions where each one creates a single new feature, promoting clarity and testability.
- Final Validation: A final check to ensure the processed data schema is exactly what the model expects.
This pattern makes your system readable, debuggable, and far more professional than a single, monolithic script. You can write unit tests for each stage, making the entire system more reliable.
The Power of a Consistent API #
Once your data is ready, you'll turn to scikit-learn, the workhorse of classical machine learning. The genius of this library lies not just in its vast collection of algorithms, but in its brilliantly consistent API design. This consistency is a design pattern in itself. Almost everything in scikit-learn follows the same simple flow:
- Instantiate an object: You create an instance of a model or transformer, like
model = RandomForestClassifier(). - Fit the object: You train it on your data with the
.fit()method. - Transform or predict: You apply the trained object to new data using
.transform()or.predict().
This fit/transform pattern is more than just convenient; it's an architectural principle that promotes predictable, readable code. You can even chain multiple preprocessing steps and a final model together into a single Pipeline object, which encapsulates the entire workflow.
This is critical because it helps you avoid a common and dangerous pitfall: data leakage. This occurs when information from your test set inadvertently influences your training process, leading to an overly optimistic evaluation of your model's performance. For example, if you normalize a feature using the mean and standard deviation of the entire dataset before splitting it, your model has already "seen" the test data. Scikit-learn's Pipeline enforces best practices by ensuring all fit operations happen only on the training data. This architectural guardrail is priceless for building trustworthy models.
Architecting Real-World Systems With Deep Learning and LLMs #
Once you have mastered data workflows, it's time to move into building the intelligent core of your applications. This is the leap from running models in a notebook to building actual, robust AI systems. It all starts with a strategic choice: your deep learning framework.
The two heavyweights you'll constantly encounter are PyTorch and TensorFlow. For an engineer, this is not a casual preference but a strategic decision with implications for development speed, deployment, and ecosystem support.
Choosing Your Deep Learning Framework Wisely #
So, PyTorch or TensorFlow? Let's analyze the architectural trade-offs.
PyTorch is celebrated for being "Pythonic." Its design philosophy aligns closely with standard object-oriented Python, making it feel intuitive. Its dynamic computation graph is a major advantage for research and rapid prototyping, as it allows for flexible model structures and straightforward debugging.
TensorFlow, conversely, was architected for production from the ground up. While it can feel more rigid, its ecosystem for deployment is unparalleled. Tools like TensorFlow Serving are designed for serving models at massive scale, while TensorFlow Lite is optimized for deploying models on mobile and edge devices.
The question isn't "which is better?" but "which is better for this job?" PyTorch excels in research and flexible, agile development. TensorFlow shines when you need a rock-solid, end-to-end production pipeline built for industrial-scale deployment.
My advice for aspiring developers is to master one and become familiar with the other. Most find PyTorch easier to learn, so start there. Once you grasp the core principles of deep learning, transferring that knowledge to another framework becomes much simpler.
The New Frontier: LLMs and Architectural Patterns #
The most significant shift in AI engineering today is the rise of Large Language Models (LLMs). Effectively using an LLM is not about prompt engineering in a chat interface; it's about architecting systems that integrate these powerful models into real-world applications. This is a pure software engineering challenge.
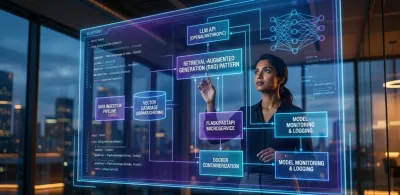
The Hugging Face ecosystem provides the tools, but you must bring the architectural vision. One of the most critical design patterns to master is Retrieval-Augmented Generation (RAG).
RAG solves the fundamental weakness of LLMs: their knowledge is static and limited to their training data. A RAG architecture connects an LLM to your own private, real-time data sources.
Here is the high-level system design:
- A user submits a query to your application.
- Your system first retrieves relevant documents from a proprietary knowledge base (e.g., a vector database of your company's support articles).
- This retrieved context is then dynamically injected into the prompt sent to the LLM.
- The LLM generates an answer using both its general knowledge and the specific, timely context you provided.
This pattern is a game-changer, enabling you to build applications like a Q&A bot that knows your company's latest internal policies or a customer service agent that can access real-time order information.
From Models to Fault-Tolerant Services #
Integrating LLMs forces you to think like a systems architect. You are no longer just building a model; you are building a service that must be reliable, scalable, and resilient.
This introduces classic software engineering problems. How do you manage conversation state in a chatbot? You'll need to design a stateful API.
What happens if the third-party LLM API you're calling is slow or fails? A resilient system requires robust error handling, retry mechanisms, and possibly a caching layer to ensure your application remains responsive. These are architectural, not model-tuning, challenges.
Mastering these patterns is what elevates you from someone who just uses AI to someone who engineers intelligent, reliable systems. You can dive deep into these concepts in our course on AI engineering with LLM APIs, where we focus on building exactly these kinds of production-ready applications.
A Project-Based Roadmap to Becoming an AI Engineer #
Alright, let's move past the theory. Knowing the tools is one thing, but building a career in AI is another. This is where we stop just learning and start building with a purpose.
Why? Because hiring managers have seen a thousand Jupyter Notebooks. They are not impressed by a script that makes a prediction in a vacuum. What they desperately want to see is proof that you think like an engineer—that you can design, build, deploy, and maintain real software that solves a real problem.
This roadmap is designed to give you that proof. It’s a project-based path that gets progressively more complex, mirroring the engineering challenges you'll face on the job. The goal isn't just to "do projects." It's to build a portfolio that communicates, "I am an engineer who ships complete, documented products."
The AI world moves incredibly fast. Just look at how quickly the major frameworks and concepts have evolved.
The rapid jump from foundational frameworks like PyTorch and TensorFlow to the recent explosion of LLMs shows why an engineering-first mindset is so critical. The tools will always change, but solid engineering principles are timeless.
Stage 1: The Foundational API Project #
Your first mission is to demonstrate that you can solve a business problem from end to end. I want you to completely forget about just training a model for a moment. Instead, you're going to build and deploy a full-blown microservice.
A fantastic starting point is a customer churn prediction API. This project immediately forces you out of the "data scientist" mindset and into an "AI engineer" one. You'll be responsible for the entire software lifecycle: data cleaning, feature engineering, model training, and—most importantly—wrapping the whole system in a REST API using a framework like Flask or Django Ninja.
The secret here is that the model's accuracy is the least interesting part. The real learning comes from the engineering decisions. How do you structure your API endpoints for clarity and scalability? How do you validate incoming data to prevent bad requests from crashing the service? How are you logging predictions and errors for monitoring?
Answering these questions demonstrates a level of engineering maturity that a simple model script cannot. It proves you understand that a model is just one component in a much larger, functional system.
Stage 2: The Complex Data Pipeline Project #
Once you've shipped a working API, it's time to increase the complexity. Now you'll tackle a project with messy, unstructured data, which will force you to design a more sophisticated data pipeline. This is your opportunity to dive into a specialized domain like Natural Language Processing (NLP) or computer vision. The real focus here remains on the architecture of the pipeline, not just the final model.
For example, try building a sentiment analysis tool for product reviews. This project presents a new class of challenges because you're dealing with unstructured text. You'll be forced to architect solutions for:
- Text Preprocessing: How do you design a system to handle raw, messy text? What is your strategy for cleaning, tokenizing, and normalizing it?
- Feature Extraction: What are the architectural trade-offs between classic TF-IDF and modern word embeddings like Word2Vec or GloVe?
- Pipeline Architecture: How do you structure this multi-step process so that it is both efficient and maintainable?
Nailing this stage proves you can do more than just work with clean, pre-packaged tabular data. It shows you can architect a system that transforms chaotic, real-world data into a format that a model can reliably consume.
Stage 3: The End-to-End Capstone Application #
This is your flagship project. Your capstone should be a complete, self-contained AI application that showcases your full range of engineering skills. The goal is to build something that looks and feels like a real, deployable product. A Q&A bot built with a Retrieval-Augmented Generation (RAG) architecture is an absolutely perfect choice for this.
This project integrates all your skills into one cohesive system:
- System Design: You have to architect the entire application—a user interface, a backend API, a vector database to store your knowledge, and the integration with a third-party LLM.
- Containerization: You'll package the entire multi-service application using Docker, proving you can create a single, reproducible artifact that can be deployed anywhere with a single command.
- Documentation: You’ll write a professional-grade
README.mdon GitHub. This isn't an afterthought; it should clearly explain the problem you're solving, your architectural choices, and provide dead-simple instructions for running the application.
A project like this makes a powerful statement. It tells a hiring manager you don't just "do AI"—you engineer solutions. You can take a complex idea from concept to a documented, containerized, and functional application. It's the ultimate proof that you're ready for a real-world engineering role.
Frequently Asked Questions About Becoming an AI Engineer #
Once you move beyond basic tutorials, the real questions emerge—the strategic ones that shape your career and separate hobbyists from professional engineers. Let's address some of the most common high-level questions.
Do I Need Advanced Math to Start With AI Programming? #
Absolutely not. You do not need to be a math expert with a deep understanding of calculus, linear algebra, and statistics before you write your first line of AI-related code. This is a pervasive myth that unnecessarily holds people back.
Think of it this way: you don't need to understand the physics of an internal combustion engine to become a great driver. You learn to operate the vehicle first. Later, if you want to become a performance engineer and tune the engine for maximum output, you can dive deep into the mechanics.
The same principle applies here. Start by building practical applications. Use high-level libraries like scikit-learn and PyTorch to solve tangible problems. You'll build momentum and stay motivated. The need for deeper mathematical knowledge will become apparent when you encounter limitations, and at that point, you'll learn it with a clear purpose. Let application guide your study of theory, not the other way around.
Which Is Better to Learn First: PyTorch or TensorFlow? #
For anyone starting their journey as a software developer in AI, I almost always recommend PyTorch. Its API is famously "Pythonic," meaning it feels more intuitive and natural if you already have a solid grasp of object-oriented Python.
From a learning and development perspective, the debugging experience alone makes it the winner for beginners. The dynamic computation graph in PyTorch is simply easier to troubleshoot when things go wrong—and they will.
TensorFlow is a powerhouse for large-scale production systems, with a mature and robust ecosystem for deployment (like TensorFlow Serving). However, this production focus can introduce a steeper learning curve. Master your fundamentals with PyTorch. Once you truly understand deep learning principles, adapting to TensorFlow for a specific job requirement will be a straightforward task.
How Do I Build a Portfolio Without Real-World AI Experience? #
This requires a crucial mindset shift. Stop thinking like a data scientist collecting Jupyter Notebooks and start thinking like a software engineer shipping a product. A hiring manager is less interested in a messy notebook and more interested in seeing that you can build and deploy a complete, working application.
Take a model you’ve trained and architect a simple REST API around it to serve predictions. But don't stop there. Go further to demonstrate your understanding of the entire system lifecycle:
- Containerize your app with Docker. This proves you understand how to create portable, reproducible software environments—a critical skill for any team.
- Write an excellent README. Your GitHub repository should function as a mini-product page. Clearly document the problem you're solving, the architectural decisions you made, and provide precise instructions on how to run your application.
This approach demonstrates that you think about the entire lifecycle of a product, from development to deployment and maintenance. It proves you can deliver end-to-end value, which is the skill that gets you hired.
At Codeling, we focus on building these exact engineering-first skills. Our platform isn't about theory; it's a hands-on curriculum where you build and deploy portfolio-ready applications from day one. You'll master the real-world architecture that employers are desperately looking for.
Start your journey and build your first AI-powered API with us today. Learn more about our structured Python curriculum.